
total_activ
네트워크보안 v.02 _ TCP/IP Networks 공부 (UDP/TCP) 본문
UDP: User Datagram Protocol
UDP

IP 데이터 그램 = IP 헤더(20) +UDP 데이터 그램 = IP 헤더(20) + {UDP 헤더(8) + UDP 데이터}
Simple, datagram-oriented, transport layer protocol
신뢰성을 전혀 지원하지 않음
응용이 쓴 데이터 그램은 IP 계층에 전달되지만, 목적까지 도착한다는 보장은 어디에도 없음
이로인해 UDP 응용은 최종 IP 데이터그램의 크기를 고려 중요
네트워크의 MTU를 초과하는 UDP/IP 데이터그램이 분활됨 (fragmented)
뒤에서 더 자세히 다룰 예정
UDP Header

{16-bit source port number + 16-bit destination port number + 16-bit UDP length + 16-bit UDP checksum}(8) + DATA
Port number 필드
sending process와 receiving process 구별에 이용
보통 TCP포트 번호와 UDP 포트 번호를 나누어 관리하지만, TCP 포트 번호는 UDP 포트 번호에 "독립적"임
-> 즉, 전송 계층 프로토콜이 다르면 포트 번호는 중복이 허용됨

UDP lenght 필드 : UDP header + data(total length)의 길이
최소 크기는 8바이트(data 길이 0)임 : data가 비어도 무방함
IP 길이 필드에 IP 데이터그램의 총 길이가 명시되고, UDP는 옵션 없이 고정 헤더 길이를 쓰므로, 사실 필요 없는 필드임
UDP Checksum
IP 헤더의 체크섬 필드는 IP 헤더만 체크하지만, UDP 체크섬은 헤더와 데이터 전체를 체크한 결과임
IP 체크섬 (16비트 워드 단위로 1의 보수 합)과 다른점
IP 헤더는 바이트 단위로 4의 배수라서 언제나 16비트 워드 반위로 표현해도 정수로 표현되는데 , UDP 데이터그램은 아님
- UDP 데이터 크기가 홀수 바이트라면, 0으로 채운 1바이트 패딩 추가
- 패딩은 체크섬 시에만 사용되고 실제 전송되지 않음
IP의 일부 필드로 12바이트의 가상 헤더를 만들어 체크섬 시 사용
- 이 때 UDP 데이터그램 길이는 두번 반복됨
전송된 체크섬 필드값이 0이면, 체크섬이 사용되지 않았음을 나타냄
UDP checksum 계산시 활용되는 필드들
의도적으로 데이터가 홀수 바이트로 가정함 (PAD 필요)

UDP 체크섬은 중단간 체크섬임
중간 bit 에러 되도 최종에서 발견됨 -> TCP 재선송, UDP 버림(ex. 비디오)
송수신 주체 외의 누군가가 헤더나 데이터를 수정했을까 확인
체크섬 에러가 발생한 UDP 데이터그램은 "조용히" 폐기됨
UDP 표준 문서는 체크섬의 사용을 선택사항으로 표기함
하지만 Host Requirements RFC에서 디폴트로 UDP 체크섬의 사용을 요구함
-반면, TCP는 체크섬의 사용은 TCP 표준 문서상에서도 의무임
Host Requirements RFC 등장 전인 1980년대, 속도를 빠르게 하려고 몇몇 회사들이 UDP 체크섬을 껐는데, LAN에서는 보통 체크섬이 있는 경우가 많아 문제가 안되었지만, 인터넷에서는 라우터의 버그로 비트가 바뀌는 경우가 있어서 문제가 됨 -> 더구나, SLIP 같이 같은 링크 계층에 체크섬이 없는 경우도 있음
TCPdump를 활용하여 각 호스트 별 Checksum 사용 여부 확인
응용에서는 UDP 체크섬에 대한 정보를 볼 방법이 없음
이에 링크 계층에서 패킷 캡쳐를 하는 TCPdump 소스를 수정해 UDP 체크섬을 출력하게 함
(sock프로그램이 9바이트 UDP 데이터 그램 생성)
- UDP cksum=0은 송신 호스트가 UDP 체크섬을 지원 안 한다는 의미
체크섬 알고리즘 상, 3/4, 5/6이 동일한 체크섬을 갖는데 각 페어가 16피트 크기의 필드 값 위치가 바뀌었을 뿐이기 때문
- 즉, 체크섬 알고리즘은 그러한 필드 값 위치 변경을 탐지 못함
0.0 sun. 1900 > gemi ni . echo: udp 9 ( UDP cksum=6e90)
0. 303755 ( 0. 3038) gemi ni . echo > sun. 1900: udp 9 ( UDP cksum=0)//checksum 사용 안함
17. 392480 ( 17. 0887) sun. 1904 > ai x. echo: udp 9 ( UDP cksum=6e3b) //SRC,DST 자리는 변경되지만 값은 동일하기에 합 동일(field 교환법칙 성립)
17. 614371 ( 0. 2219) ai x. echo > sun. 1904: udp 9 ( UDP cksum=6e3b)
32. 092454 ( 14. 4781) sun. 1907 > sol ar i s. echo: udp 9 ( UDP cksum=6e74) //echo : 보낸거 그대로 보여달라는 뜻
32. 314378 ( 0. 2219) sol ar i s. echo > sun. 1907: udp 9 ( UDP cksum=6e74)Mogul 1992
40일 가동한 NFS 서버의 체크섬 에러 통계임
TCP 체크섬 에러가 총패킷수 대비해서 봐도 UDP보다 많은데 장거리 동작을 하기 때문으로 보임
- UDP 트랙픽은 근거리라, 에러 날 확률 자체가 낮고 링크 계층 체크섬이 있어 적은 것임
그럼에도 불구하고 에러는 발생한다고 봐야함
- 1K byte 패킷 크기를 가정해도, 근거리에서 140TB 전송시 5개는 문제가 생김 (심지어 발견 안될수도 잇음)
- 그냥 UDP 체크섬을 키면된다라는 것이 결론
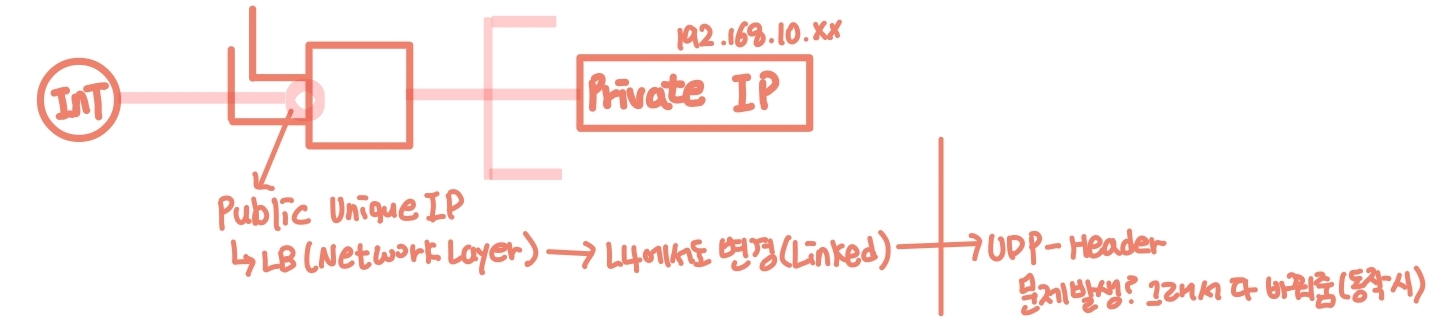
IP Fragmentation
IP Fragmentation (IP계층)
상위 계층에서 보내온 데이터 단위는 우너칙적으로 한 IP 데이터그램에 담기는데, 최초 송신 호스트에서 또는 중간 라우터에서 IP 데이터그램을 여러개로 분할한것 -> 쪼개는 기준은 MTU
IP Fragmentaton이 필요한 상황
IP 데이터그램의 크기가, 보내는데 쓰려는 링크 계층이 전송할수 있는 MTU보다 클때
- Fragmentation이 여러 홉에서 일어날 수도 있음
- 링크 계층의 MTU 크기는 인터페이스에 쿼리를 보내 확인함
IP Ressembly (IP 데이터그램 재조합)
분활된 IP 데이터그램들을 한 IP 데이터그램으로 재조합하는 것으로, 최종 목적지에'만' 수행함
- 다른 프로토콜들은 다른 홉에서 재조합을 하기로 함
전송계층에 투명하게 분할 및 재조합을 하는 것이 목적
Fragmentation 관련 IP 헤더 필드
Identification 필드: 송신자에서 보낸, (아직 분할되지 않은) 각 IP 데이터그램에 대한 “유일한 (unique)” 식별자
-분할될 경우, 각 단편 (fragment)의 Identification 필드에 복사됨
Flags 필드
- MF (more fragment) 비트: 본 단편 뒤에 송신된 단편이 있음을 알림 (마지막 단편에는 MF 비트를 설정하지 않음)
- DF (don’t fragment) 비트: DF가 설정되면, IP는 datagram을 단편화하지 못하 고 폐기함.
대신 ICMP error를 최소 송신자에게 보냄 “fragmentation needed but don’t’ fragment bit set”
Fragment offset 필드: 해당 단편이 원래 데이터그램의 첫 바이트에서 몇 바이트 뒤의 데이터인지를 명시
Total Length 필드: 원래 데이터그램의 총 길이가 아닌 각 단편의 총 길이를 기재함
Routing of Fragments
각각의 단편은 자신의 IP 헤더를 갖는 독립된 패킷
다른 패킷과 독립적으로 전송, 최종 목적지에 다른 순서로 도착할 수 있지만 IP 헤더로 재조립
Fragmentation의 단점
단편 하나라도 분실하면 데이터그램 전체의 재전송이 요구되나, IP는 자체 재전송을 할 수 없음 (상위 계층의 책임임)
- TCP는 재전송 요청, UDP 버림
- IP는 재전송/타임아웃이 없어서, 보낸 데이터그램을 기억하지 않기 때문
더군다나, 중간 라우터에서 Fragmentation이 일어났다면, 송신자는 데이터그램의 분할 여부조차 알 방법이 없음
이 때문에 [Kent and Mogul 1987]은 Fragmentation을 피해야 한다고 주장함
- Kent, C. A., and Mogul, J. C. 1987. “Fragmentation Considered Harmful,” Computer Communication Review, vol. 17, no. 5, pp. 390-401. (Aug.)
Fragmentation 예제
(1500= 1472 + 20 + 8)
sock 프로그램으로 1471바이트부터 1474바이트 UDP 데이터 전송
- Ethernet 의 MTU = 1500 bytes
- 최대 크기 (無분할) = 1500 - 20(IP header) - 8(UDP header) = 1472 bytes
주의사항: 생성된 fragment의 크기는 마지막 fragment를 제외하고 8의 배수가 되어야 함 (표준 요구사항)
Note: 이 책에서는 표준에 맞게 Datagram과 Packet을 부름
0.0 bsdi . 1112 >svr 4. di scar d: udp 1471
21. 008303 ( 21. 0083) bsdi . 1114 >svr 4. di scar d: udp 1472 // 1472(+8)까지는 MTU 1500을 안넘기기 때문에 쪼개지 않음
50. 449704 ( 29. 4414) bsdi . 1116 >svr 4. di scar d: udp 1473 ( frag 26304: 1480@0+)//IP ID 필드값은 26304, UDP 헤더를 포함한 1480byte IP 데이터 크기, offset은 0, MF비트는 +
50. 450040 ( 0. 0003) bsdi >svr 4: ( frag 26304: 1@1480) //ID는 26304와 동일, 1바이트 데이터 크기, 1480부터 시작하는 Offset
75. 328650 ( 24. 8786) bsdi . 1118>svr 4. di scar d: udp 1474 ( frag 26313: 1480@0+)//1480 = 8의 배수임
75. 328982 ( 0. 0003) bsdi >svr 4: ( f r ag 26313: 2@1480) //맨앞 packet에서만 UDP 헤더가 존재위 실험을 Linux에서 한 결과
마지막 단편을 먼저 보냄
- 이럴 경우, 구현의 입장에서 데이터그램의 총길이를 알 수 있어서 버퍼 공간을 미리 할당하기 좋음
BUT, 거꾸로 UDP 포트 번호를 미리 알수 없어서 첫번째 단편을 먼저 보내는 것이 좋다는 의견도 있음
- [KEWG96] F. Kaashoek, D. Engler, D. Wallach, and G. Ganger, “Server Operating Systems,” Proc. SIGOPS European Workshop, 1996
ICMP 도달 불가 에러 [단편화 요구]
Path MTU Discovery 메커니즘 [RFC1191]에서 사용
– 하지만 못 쓰는 상황도 있을 수 있음에 주의
못 쓰는 예제 (solaris가 600 바이트 데이터의 ping packet 보냄)
- Solaris는 DF를 디폴트로 설정
- Netb의 SLIP MTU는 실제론 1500으로 설정된 상황임
- sun -> bsdi DF라 쪼개지못하고 ERROR 메세지 전송
UDP를 이용한 Path NTU 발견
앞의 예제와 같은 상황이 아니면 Path MTU Discovery를 통해서 IP가 Path MTU를 학습할 수 있음
- Solaris 2.2의 IP는 Path MTU Discovery를 지원함
tcpdump output on sun
0.0 solaris.36196>slip.discard:udp 650 (DF)
0.004218 (0.0042) bsdi>solaris: icmp:
slip unreachable - need to frag, mtu=0 (DF) //MTU는 모른다. 하지만 요즘은 알려줌
4.980528 (4.9763) solaris.36196>slip.discard:udp 650 (DF) //중간에 깨진줄 알고 재전송
4.984503 (0.0040) bsdi>solaris: icmp:
slip unreachable - need to frag, mtu=0 (DF)
9.870407 (4.9763) solaris.36196>slip.discard:udp 650 (frag 47942:552@0+) //572=IP(20)+UDP(8)+548->480+64=544->544+UDP(8)->552 (운영체제 규칙)
9.960056 (0.0896) solaris>slip: (frag 47942:106@552)
14.940338 (4.9763) solaris.36196>slip.discard:udp 650 (DF)//Time Out되서 DF 다시 설정
14.944466 (0.0040) bsdi>solaris: icmp:
slip unreachable - need to frag, mtu=0 (DF)
19.890015 (4.9763) solaris.38196>slip.discard:udp 650 (frag 47944:552@0+)
19.950463 (0.0604) solaris>slip: (frag 47944:106@552)
…
44.940485 (5.0100) solaris.36196>slip.discard:udp 650 (DF)
44.944432 (0.0040) bsdi>solaris: icmp:
slip unreachable - need to frag, mtu=0 (DF)2 : 아쉽게도 bsdi가 구식이라 MTU를 안 알려줌. 저자는 bsdi를 수정해 296을 알려주는 실험도 수행하며, 이 때 solaris는 5번 패킷에서 576 대신 296으로 설정
3 : Solaris의 Path MTU Discovery는 한번에 학습을 못함
5 : Solaris가 드디어 학습. 단, MTU를 576으로 가정 (Host Req. RFC의 요구사항이기 때문으로, mtu=0인 상황에서 합리적인 선택임)
7, 19 : Solaris의 IP 계층이 30초 timeout이 지나서 DF를 다시 설정 (RFC 1191은 10분으로 추천)
tcpdump output on slip
- 최초의 데이터그램 수신만 표기하였음
0. 0 solaris. 38196>slip. discard: udp 650 ( frag 47942: 272@0+)
0. 304513 ( 0. 3045) solaris>slip: ( frag 47942: 272@272+)
0. 334651 ( 0. 0301) solaris>slip: ( frag 47942: 8@544+)
0. 0. 1320 ( 0. 1320) solaris>slip: ( frag 47942: 106@552)
650 -> 544(544+8) + 106 -> {264(272) + 272 + 8} + 106
- Solaris가 576 바이트로 fragmentation을 했지만, bsdi가 다시 한 번 fragmentation하였기 때문에 실제 MTU는 296바이트임
결론
- Path MTU Discovery 메커니즘이 있으면 UDP에서 IP Fragmentation 문제에도 데이터 전송이 가능
- 하지만, 응용에서 재전송을 반드시 처리해주어야 함
- 또한, 학습한 Path MTU는 timeout으로 사라질 수 있다는 점을 UDP를 사용하는 응용이 세심히 고려해야 함
UDP와 ARP간의 상호 작용
어떤 구현(bsdi)에서는 매 단편이 ARP 요청을 만들어 냄
- Host Requirements RFC (RFC1122)는 이런 ARP Flooding (동일 IP 주소로 동일 ARP 요청을 빠르게 보내는 것)을 막고자 1초에 1개의 요청만을 보내도록 추천하기에, 이 상황은 문제가 있음
ARP는 ARP 응답이 오기 전에 unresolved 상태의 동일 목적지로 가는 여러 패킷이 도착하면, 하나 이상의 패킷을 저장
- 이 또한 RFC1122의 요구사항 (SHOULD)임
- 대부분의 구현은 마지막 패킷만 저장함 (버퍼가 1개라는 의미)
따라서, 매 단편이 ARP 요청을 만들면, 위와 같은 구현에서는 한 단편 외에는 모두 폐기되고 맘
본 책의 2판에 따르면 Linux에서는 이러한 문제가 관찰되지 않았음 (단, 코드를 분석하여 얻은 게 아니라 실험한 결과임)
# 모든 Packet에 대한 ARP가 해야할것같지만 1초에 하나만 가기 때문에 cache로 해결한다
UDP 데이터그램 크기의 최대값
이론상, IP 데이터그램의 최대 크기는 65,535 bytes
- IPv4의 Total Length 필드가 16 bit라서
따라서 UDP 데이터그램의 최대 크기는 바이트 단위로 65,535 – 최소 IP헤더 크기 (20) – UDP 헤더 크기 (8) = 65,507
IPv6의 경우, Total Length 필드가 없어지고 16비트의 Payload Length 필드가 사용되므로, 65,527 바이트임
- 점보그램을 사용하지 않는다는 가정 하에
하지만, 이론상 최대 크기로 보내는 경우는 거의 없음
- 시스템의 프로토콜 구현에 한계가 있기 때문에
- 수신 응용이 그런 큰 UDP 데이터그램을 처리 못하기 때문에
구현 측면에서의 한계
프로토콜 구현들은 송수신용 버퍼 크기를 정하는 API를 제공하며, 이 크기는 응용이 읽고 쓰는 UDP 데이터그램의 최대 크기를 결정함
- 최근엔 8,192 바이트 또는 65,535 바이트가 디폴트임
- 그런데, 몇몇 구현에서 디폴트 값은 최대 IP 데이터그램 크기보다 작도록 해 둠…
- 몇몇 구현에서 수십 KB 이상 보내는 걸 막는 경우조차 있음 (드물지만)
3.2절에서, 호스트는 최소 576 바이트의 IP 데이터그램을 받을 수 있어야 함
- 다시 말해 576 바이트가 넘는 IP 데이터그램을 받지 못하는 호스트도 있다는 것(!)
- 때문에, 많은 UDP 응용들은 512 바이트 이하의 응용 데이터를 보냄 (DNS, DHCP등)
데이터그램 절단 (Datagram Truncation)
송신자가 수신자의 버퍼 크기보다 큰 UDP 데이터그램을 보내면, 대부분의 응용이 초과 부분을 절단해버림
- 문제는, 어떤 구현은 다음 read 함수 호출에 나머지를 주기도 하고, 다른 구현은 절단된 양을 알리기도 하고, 또 어떤 구현은 데이터가 절단되었다는 사실만 알리기도 하고…
TCP 서비스
TCP 서비스:
UDP와 같은 네트워크 계층(IP)을 이용
UDP와는 완전히 다른 서비스를 응용 계층에 제공
연결지향의 신뢰성있는 바이트스트림 서비스를 제공
- "TCP provides a connection-oriented, reliable, byte stream service" 문장 자체를 달달 외울 것
연결-지향(connection-oriented) 서비스의 의미

두 응용 프로세스 (보통 클라이언트, 서버)가 데이터를 교환 하기 전에 서로 TCP 연결을 확립함을 의미
Three-way handshake
- 예) 전화 시에 상호간 준비가 되었음을 알리기 위해 Hello라는 인사말을 서로 교환하는 것처럼...
신뢰성(Reliability) 서비스
1. 정보단위인 세그먼트를 IP로 전송함
응용이 보내는 데이터는 TCP가 전송하기 적합한 크기로 나뉘어짐
- 반면, UDP는 각 응용이 UDP 데이터그램을 적절한 크기로 만들어 줌
적절한 세그먼트 크기 결정은 18.4절 참조

2. TCP는 세그먼트를 보낼 때마다 타이머를 설정(21장 참조)
수신측으로부터 확인 응답 (ACK) 메세지를 기다림
확인 응답이 오지 않을 경우 세그먼트를 재전송

3. TCP가 연결의 상대편으로부터 데이터를 받으면 확인응답을 보냄
보통 짧은 시간 (<1초?) 동안 지연된 후에 보내짐 (19.3절 참조)
4. end-to-end checksum: TCP는 헤더와 데이터에 검사합(checksum)을 함
데이터가 전송 중에 변화되었는지 검출하는 것이 목적
오류가 난 세그먼트는 버리고 확인 응답을 보내지 않음 (송신자의 타임아웃과 재전송을 기다림)
5. TCP 세그먼트는 IP 데이터그램 형태로 전송되므로, 순서를 지키지 않고 (out of order) 수신측에 도착할 수 있음 / 수신측 TCP는 필요시 데이터를 재정렬해, 정확한 순서대로 응용에 전달
6. IP는 라우팅 과정에서 중복이 발생해도 이를 허용하나, 수신측 TCP는 중복된 데이터를 반드시 폐기함
시간 차이등으로 발생한 중복도 하나를 버리고 진행함

7. TCP는 흐름 제어 (flow control)를 제공함
TCP 연결의 각 종단은 유한한 버퍼를 가짐
수신측 TCP는 버퍼용량을 초과하지 않는 범위의 데이터만 버퍼에 저장
- 송신측 TCP은 수신측 TCP의 빈 버퍼 공간만큼만 보내도록 제어됨
(즉, 송신측 호스트가 너무 빨라서 느린 호스트의 버퍼를 다 쓰는 문제를 방지함

바이트 스트림 서비스 (bytestream service)

TCP 연결을 통해서 양방향의 8-bit byte stream이 교환됨
- 응용에 full-duplex 서비스를 제공: 입력 스트림과 출력 스트림이 독립됨
TCP는 레코드 구분자 삽입 기능을 전혀 지원하지 않음
- 응용은 메세지를 구분하는 단위인 레코드 구분자가 필요시, 알아서 삽입해야 함
TCP는 바이트에 대한 해석을 전혀 하지 않음
# Note: TCP의 주요 서비스를 설명하는데 왜 혼잡 제어는 없을까?
- "Congestion control is not so much a service provided to the invoking application as it is a service for the Internet as a whole, a service for the general good." quoted from J. F. Kurose and K. W. Ross, Computer Networking, 7th Ed., Pearson, 2017.
- 사실, 위 세 서비스는 RFC 793 (1981)에 명시된 것이므로, 그 시절엔 혼잡 제어도 없었음
TCP 헤더
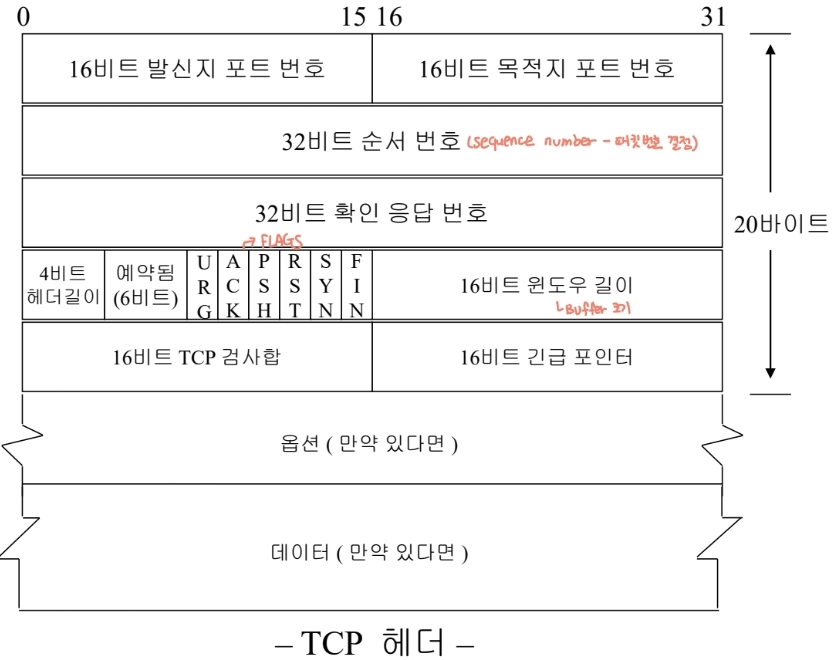
포트 번호(port number) 필드

TCP 세그먼트를 송신하고 수신하는 응용을 구분하기 위해서 사용
IP 주소 하나와 포트 번호 하나의 조합을 소켓(socket)이라고 함
- 클라이언트와 서버의 두 소켓을 묶어서 socket pair라고 함
- socket pair는 인터넷 상의 TCP 연결을 유일하게 식별하는데 사용 가능한 식별자임
순서 번호(sequence number) 필드

송신 측의 TCP로부터 수신 측의 TCP로 가는 데이터 스트림의 바이트를 구분하기 위해 매 바이트에 붙여진 번호
- 일종의 byte-address 메모리 주소로 생각할 수 있음
32비트 부호 없는 번호로서 0부터 232 − 1을 초과하면 다시 0부터 시작
새로운 연결을 확립하는 과정에서, 세그먼트에 SYN 플래그가 설정될 경우, 순서 번호 필드에는 호스트가 연결에 선택한 초기 순서 번호(ISN)을 기재함
- 이때, SYN 플래그는 1바이트를 소모한다고 가정(즉, 송신 측의 첫 데이터는 ISN+1)
확인 응답 번호(acknowledgement number; ACK number) 필드

수신한 마지막 바이트의 순서 번호 + 1을 기재함
- 즉, 다음 수신할 첫 바이트의 순서 번호를 나타냄
이 필드는 ACK플래그가 설정 되어 있을 때만 유효
- 연결이 설립된 이후엔 계속 ACK 플래그가 설정됨
TCP에서 순서 번호와 확인 응답 번호의 특징
TCP는 각 방향으로 데이터를 흘려보내는 full-duplex 서비스를 응용에 제공 함 (동시 수송신 가능)
- 따라서, 연결의 각 종단 호스트는 각 방향에 대한 순서 번호를 저장하고 관리해야 함
TCP는 Selective ACK(SACK)나 Negative ACK(NACK)를 지원하지 않는 슬라이딩 윈도우 프로토콜의 일종임
- 확인 응답 번호 필드의 의미 상, 먼저 도착한 세그먼트나 손상된 세그먼트에 대한 정보를 알릴 수 없음
- 참고: SACK의 경우 TCP 옵션으로 추후 추가되긴 함
Cumulative ACK: 어디까지 전송이 완료되었는지 송신자에게 알림 (sliding window)
4비트 헤더 길이(header length) 필드
'32비트 워드' 단위로 헤더의 길이를 명시함
- 옵션 필드로 인해 헤더가 길이가 변할 수 있어 필요함
4비트밖에 안 되므로, 60바이트 헤더로 길이가 제한됨
- 옵션이 없는 일반적인 경우엔 20바이트임 (즉, 필드값 = 5)
6개의 플래그 비트
URG 긴급 포인터가 유효함 ( 20.8절 )
- URGent Pointer에 값이 유효한다. 거의 사용되지 않는다. (긴급처리 데이터)
ACK 확인응답 번호가 유효함
PSH 수신측은 데이터를 가능한 빨리 응용으로 보내야 함.( 20.5절)
- 빨리 보내라
RST 연결을 재설정 ( 18.7절 )
- 강제 연결 종료 후 재전송하겠다.
SYN 연결을 초기화하기 위해 순서 번호를 동기화 ( 18장 )
FIN 송신 측이 데이터 전송을 종료함 ( 18장 )
- 정상적 연결 종료 (fin, Ack - 4way handshack)
검사합(checksum)필드
TCP header와 TCP data에 모두에 대한 checksum
필수 필드로서 송신 측에서 계산, 저장되고 수신 측에서 검사됨
11.3절에 소개된 UDP 검사합과 같은 의사(pseudo) 헤더를 이용하여 계산
긴급 포인터(URGent pointer) 필드
(데이터 필드 앞부분에 삽입된) 긴급 데이터의 크기를 나타냄
URG 플래그가 설정되어 있을 때만 유효
송신 측이 상대편에게 긴급한 데이터를 보낼 수 있음 (20.8절)
- 긴급 데이터는 순서 번호에 계상되지 않음
요즘은 거의 안 쓰임 (쓴다면, 보안 공격용?)
출처 : Hoorin Park Assistant Professor, Department of Information Security, Seoul Women’s University
'공부' 카테고리의 다른 글
| 네트워크보안 v.04 _ TCP/IP Networks 공부 (TCP 연결 수립&종료) (0) | 2022.10.11 |
|---|---|
| 네트워크보안 v.03 _ TCP/IP Networks 공부 (TCP) (0) | 2022.10.11 |
| 네트워크보안 v.01 _ TCP/IP Networks 공부(ARP) (1) | 2022.10.06 |
| 데통 공부 v.04 (DNS, P2P) (1) | 2022.09.20 |
| 데통 공부 v.03 (Application layer, Transport layer, HTTP, Queue) (1) | 2022.09.20 |


